Place yourself on the map.
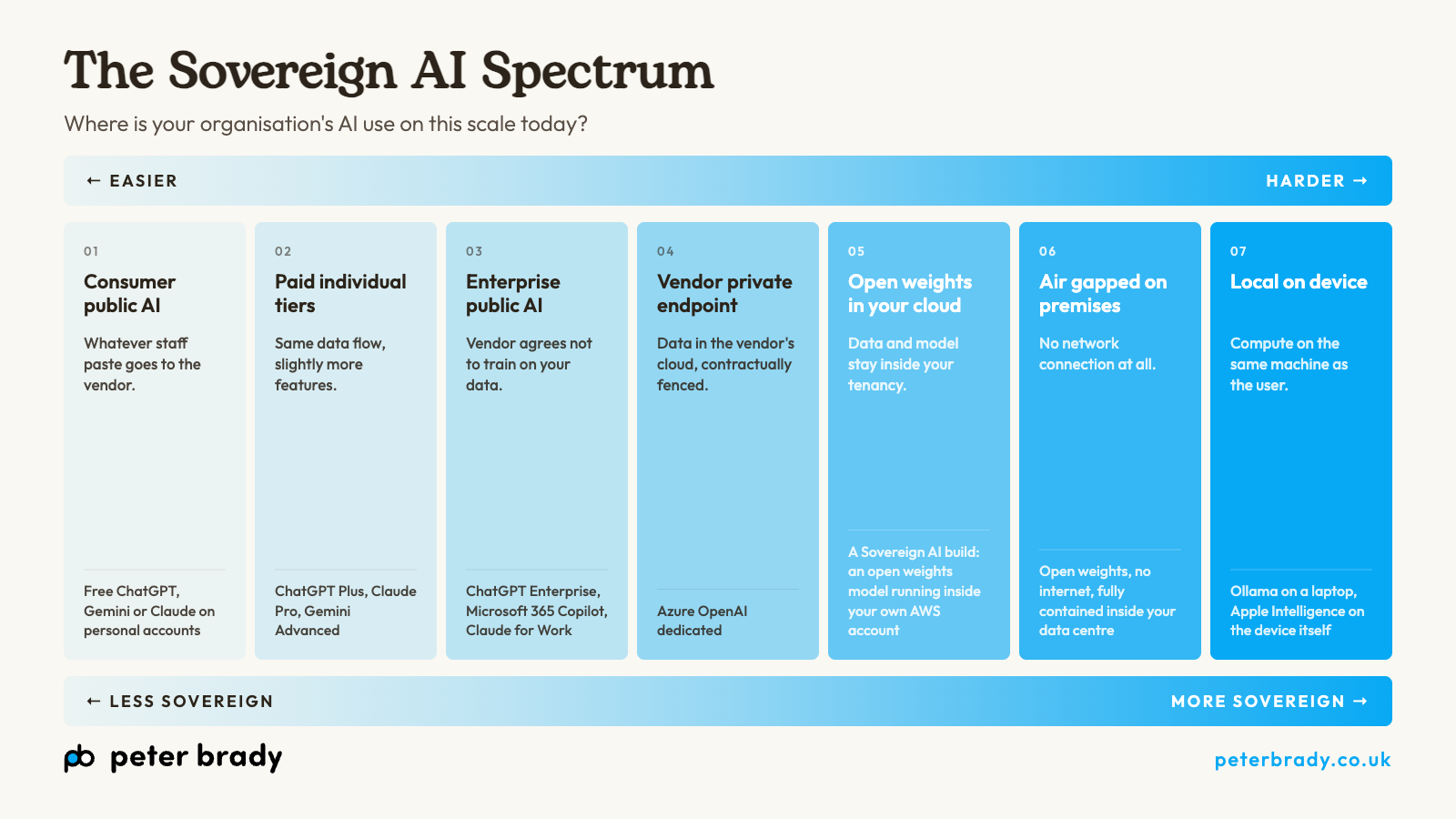
The Sovereign AI Spectrum
Where is your organisation's AI use on this scale today?
Most of the conversation about Sovereign AI treats it as a binary: an AI setup either is sovereign or it isn't. In practice it sits on a scale. Seven distinct positions, from "everything is shared with a public vendor" to "nothing leaves the device." Where your organisation sits depends on how sensitive your data is and how much operational complexity your IT team can carry.
This is the map.
How to read it
Two scales run in opposite directions. The further right you go, the more control you have over your data. The further right you go, the more your IT team has to take on. There is no single right answer. The right position is the one where your data sensitivity and your operational capacity meet.
For most organisations doing general business work, the answer sits to the left. For organisations handling sensitive client material, regulated information, or anything that would carry consequences if it surfaced in the wrong place, the answer sits further right.
01. Consumer public AI
Free ChatGPT, Gemini, or Claude on personal accounts.
Anything staff paste goes to the vendor. There is no agreement that protects your data, no logs you can access, and no governance you can apply. People often use these tools at work without anyone in IT knowing.
This is the shape shadow AI takes in most organisations. If your policy is silent on AI, this is probably where a portion of your staff already are.
02. Paid individual tiers
ChatGPT Plus, Claude Pro, Gemini Advanced.
The data flow is the same as the free tier. The user gets a few more features, faster responses, and access to better models. The protection picture does not change.
Worth knowing because staff sometimes assume "paid" means "safer." For the data flow, it does not.
03. Enterprise public AI
ChatGPT Enterprise, Microsoft 365 Copilot, Claude for Work.
The vendor signs an agreement that your data will not be used to train the model. You get documented processing terms, UK or EU data residency on most plans, audit logs, and single sign on. These are real protections.
For most organisations doing general business work, this tier is enough. The data still leaves your control, but it leaves under contract.
04. Vendor private endpoint
Azure OpenAI dedicated.
Your data goes to a dedicated endpoint inside the vendor's cloud. The model is still the vendor's, the operations are still the vendor's, but the path your data takes is more isolated than the enterprise tier above.
Useful when an organisation wants the contractual protections of enterprise AI plus some additional isolation, without yet committing to running its own infrastructure.
AWS Bedrock sits in two different places on this spectrum depending on what you do with it. Bedrock with a closed weights vendor model (Claude on Bedrock, for example) belongs here at position 4. Bedrock running an open weights model inside your own AWS account, which is what my builds use, belongs at position 5. Same service, two very different sovereignty pictures.
05. Open weights in your cloud
A Sovereign AI build: an open weights model running inside your own AWS account.
Your data and the model both sit inside your tenancy. The vendor of the model is open source; the operator of the infrastructure is you. Nothing your staff send to the assistant leaves your cloud. The whole thing is described in code you own, so you can audit it, change it, or move it.
This is what I build. It is the right position for organisations that need full data control but do not want to run their own data centre.
06. Air gapped on premises
Open weights, no internet, fully contained inside your data centre.
The most isolated practical option. No network connection at all. The model runs on hardware you own, in a room you control, with no path out to the public internet.
Defence, intelligence, critical national infrastructure. Most organisations do not need this. The ones that do, know who they are.
07. Local on device
Ollama on a laptop, Apple Intelligence on the device itself.
The model runs on the same machine as the user. There is no server, no network, no other party of any kind. The trade off is capability: device sized models are smaller and less capable than data centre sized ones.
Useful for very high sensitivity tasks where even sending to your own server is too much. Not a general use answer at the time of writing.
Where most organisations should sit
For most general business work, the answer is somewhere in positions one to three. The enterprise tier of a public AI vendor handles most ordinary use, and the contract is enough.
For organisations handling client legal advice, regulated finance, health records, or anything that would carry consequences if it ended up somewhere it should not, the answer is somewhere in positions four to six. The right place inside that range depends on how much complexity your IT team is prepared to carry.
Position seven is for a narrow set of specific tasks, not a general purpose answer.
If you are not sure which side of the line your organisation sits on, Is Sovereign AI right for you? is a short read with an honest test.
Use this map
You are welcome to share this image, drop it into your slides, or send it to a colleague who is wrestling with the same question. A link back to peterbrady.co.uk is appreciated but not required.
If you are scoping a Sovereign AI build
I run a Sovereign AI Discovery: a fixed price two week engagement to scope a private build for one specific use case. The data, the model, the rules, the infrastructure, the rough cost to run it. You get a written report with enough detail for a build team to start.